

Михајло Стојановски е QA архитект со повеќе од 12 години искуство во Quality Assurance и вкупно 17 години работно искуство во IT индустријата. Во последните 7, 8 години, тој е фокусиран на Playwright / TypeScript, развој на QA алатки и AI инженеринг. Михајло е сопственик на компанијата TEMIL Int., базирана во Скопје, преку која соработува со клиенти од Финска, Англија, Австрија и Хрватска.
Со него разговаравме за важноста на извештаите кога тестовите се во прашање.

Кој беше пресудниот момент кога сфати дека стандардните репортери не се доволни за модерен CI/CD циклус?
Искрено, немаше еден конкретен пресуден момент. Тоа беше повеќе акумулација од долгогодишно искуство.
Playwright репортите се добри и корисни, но во реален CI/CD процес често не се доволни. По секој пад на pipeline, инженерите мора да анализираат логови, да бараат зависности, да споредуваат execution context и да се обидат да разберат што навистина го предизвикало проблемот.
Некогаш причината е очигледна, но некогаш анализата може да трае долго. Она што најмногу недостасуваше беше одговорот на прашањето „зошто тестот падна?“. Стандардниот report најчесто кажува што паднало, но не секогаш дава доволно контекст за причината.
Со твои зборови, што е Playwright Oracle и која е неговата „примарна мисија“?
Playwright Oracle е интелигентен Playwright reporter кој оди чекор подалеку од класичното прикажување на резултати од тестирање.
Неговата примарна мисија е да го претвори обичниот test report во корисен инженерски сигнал. Не е доволно само да се каже дека тестот паднал. Важно е инженерот да добие контекст: што се случило, каде е ризикот, дали проблемот е flaky, инфраструктурен, performance-related или најверојатно поврзан со самиот тест или код.
Со други зборови, Oracle се обидува да го скрати патот од „тестот не успеа“ до „ова е најверојатната причина и ова е следното што треба да го провериме“.
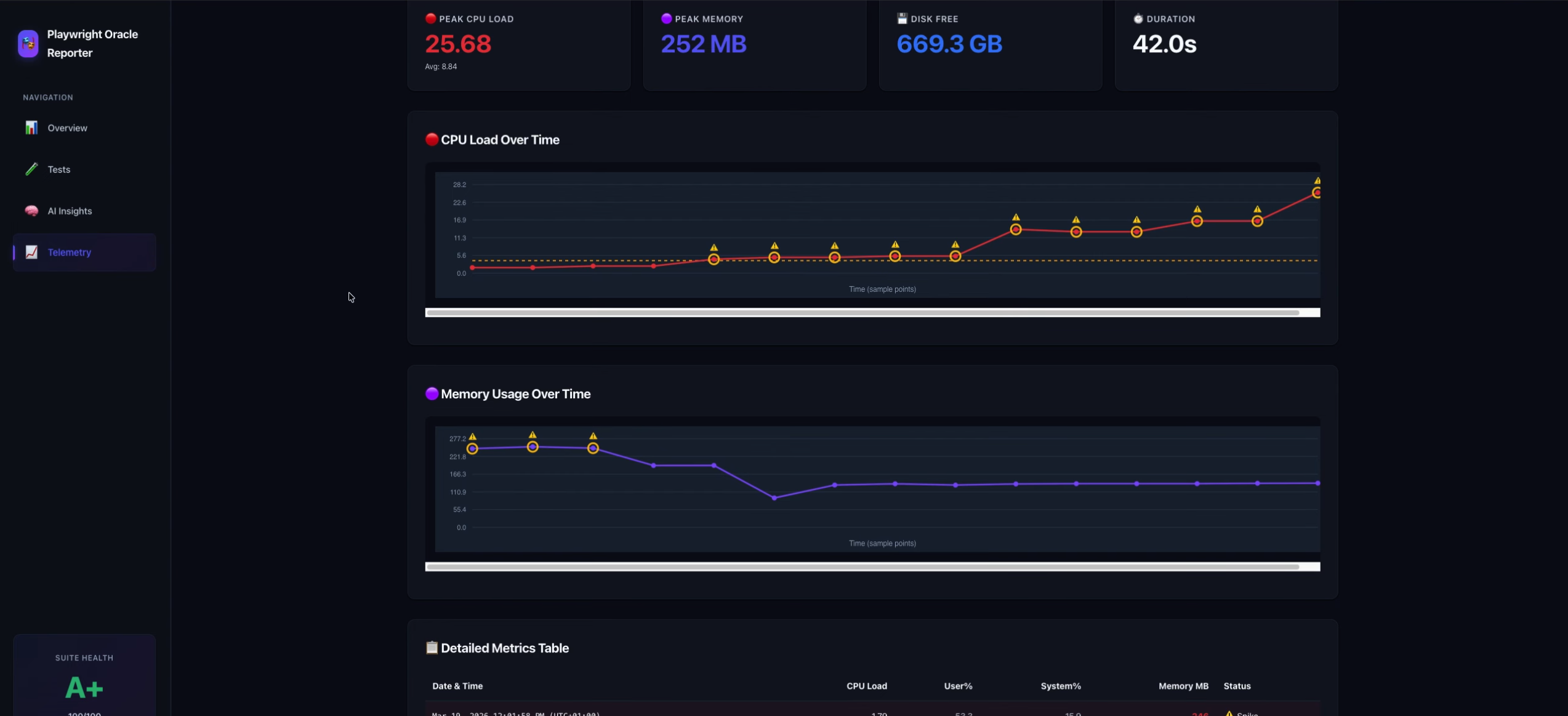
Playwright Oracle нуди runtime телеметрија. Како успеавте да го решите мерењето на ресурсите (CPU, меморија, диск) без тоа значително да влијае на перформансите на самите тестови (overhead)?
Overhead-от го решив со тоа што не се следат ресурсите агресивно и постојано, туку земаме лесни мерења во контролирани интервали. Стандардното семплирање е на 3 секунди, што според мене е добар баланс помеѓу корисен сигнал и минимално влијание врз тестовите.
Исто така, постои и конфигурациска променлива PW_ORACLE_TELEMETRY_INTERVAL, преку која тимовите можат сами да го прилагодат интервалот според своите потреби.
Мерењето е асинхроно и е направено да биде безбедно за тестовите. Ако некоја информација не може да се прочита на одредена машина или оперативен систем, Oracle ја прескокнува наместо да го блокира или расипе тестот.
Целта не е да се направи совршена performance графа, туку да се соберат доволно сигнали за да се разбере дали падовите можеби се поврзани со CPU load, мемориски притисок, disk issues или некој друг инфраструктурен фактор.
Мојата идеја беше да се избегне ситуацијата QA тимот да зависи од други тимови за да добие логови или објаснување што се случувало во моментот на пад. Со оваа телеметрија, инженерот веднаш има почетен доказ дали нешто се случувало со инфраструктурата и може многу поконкретно да разговара со останатите тимови.
Алгоритмите за детекција на flaky тестови се непроценливи во QA светот. Дали можеш да ни откриеш малку повеќе за логиката зад овие алгоритми? Како Oracle прави разлика помеѓу лош код и нестабилна инфраструктура?
Oracle, дури и без AI, не гледа само дека тестот паднал, туку се обидува да разбере зошто паднал. Прво, ги групира сличните грешки преку стабилен signature, за истиот проблем да може да се препознае низ повеќе извршувања. Потоа ги применува вградените алгоритми за препознавање на најчестите Playwright проблеми и ја анализира историјата на тестот: дали паѓа секогаш на исто место, дали некогаш поминува а некогаш паѓа, дали проблемот се јавува само на одреден browser, OS или CI runner.
Во моментот Oracle има 11 алгоритми за препознавање на вакви patterns.
Ако тестот паѓа секогаш на исто место, со исто однесување, најчесто проблемот е во тестот, кодот, locator-от или assertion-от. Ако падовите се непредвидливи, се случуваат на различни места и во исто време има висок CPU, мемориски притисок или disk проблеми, тогаш Oracle го третира тоа како можен инфраструктурен проблем.
Накратко, Oracle собира повеќе докази и му помага на тимот побрзо да одлучи каде прво да бара: во тестот, во апликацискиот код или во CI околината.
Што точно прави вештачката интелигенција што вградените алгоритми не можат?
Вградените алгоритми во Oracle се брзи и прецизни кога проблемот е познат: timeout, locator проблем, network грешка, flaky pattern или resource pressure. Тие работат по правила и кажуваат што најверојатно се случило според достапните докази. AI слојот оди чекор понатаму. Тој ги чита тие докази како инженер и прави кратко triage резиме: дали проблемот повеќе личи на инфраструктура, апликација, тест или нешто непознато. Потоа предлага можни причини, што прво да се провери и кои поправки имаат најмногу смисла.
Значи, AI не е само „читач на грешки“. Тој помага од логовите да се добие практична насока: што е најверојатната причина, како да се потврди и што да се проба како поправка. Важно е и тоа што AI е опционален. Oracle може да работи и без него, а кога се користи AI, се праќаат само исчистени текстуални податоци и метаподатоци, не бинарни trace или screenshot фајлови.
Веќе имате преку 1200 имплементации. Кои беа најголемите предизвици при претворање на интерна алатка во Open Source проект достапен на NPM?
Имплементациите растат од ден во ден. Заклучно со 5 мај 2026 година, Oracle веќе има 1628 имплементации.
Алатката ја развивав во слободно време, како проект што прво произлезе од реална потреба. Самото поставување на npm беше релативно едноставен процес — таму се следат конкретни правила и чекори. Поголемиот предизвик беше алатката да се направи доволно едноставна за користење, а сепак доволно флексибилна за различни тимови, различни CI/CD околини и различни начини на работа.
Кога нешто станува Open Source, веќе не го правиш само за својот workflow. Треба да размислуваш за документација, конфигурација, default вредности, edge cases и за тоа како некој што првпат ја гледа алатката ќе стигне до вредност што е можно побрзо.
Каков вид на тест помина репортерот? Дали имаше некој специфичен фидбек од „големите проекти“?
Највредниот feedback дојде од реални QA инженери што го користат Oracle во поголеми Playwright имплементации. Еден конкретен пример е клиент од Њу Џерси, САД, каде што дел од нивните тест сетови се доста големи. Во такви сценарија се појавија реални предизвици околу обемот на податоци, особено кога AI анализата се користи врз голем број failures. Имаше случаи каде што обемот на податоци беше доволно голем за да го оптовари Claude.
Импленетирав различни решенија за оптимизација на процесот. Сите тие оптимизации можат инженерите сами да ги прилагодуваат преку параметри во зависност од нивните потреби.
Токму такви „battle tested“ сценарија се најкорисни, затоа што покажуваат како алатката се однесува не само во мал демо проект, туку во вистинска деловна околина.
Кој е планот за проектот понатаму? Создавање на поширок екосистем кој би поддржувал и други framework-ци (на пр. Cypress или Selenium)?
Во моментов фокусот останува на Playwright. Според мене, Playwright полека го презеде приматот како алатка што сè повеќе тимови ја избираат за современ end-to-end testing. Ако се погледнат npm трендовите, Playwright е во силна нагорна линија, додека Cypress и Selenium имаат многу помал раст во споредба со него.
Затоа, наместо да се расплинам на повеќе framework-ци, сакам прво Oracle да стане што е можно постабилен, покорисен и позрел во Playwright екосистемот. Поддршка за други framework-ци не е исклучена во иднина, но моментално најголемата вредност ја гледам во продлабочување на Playwright integration-от.
Како локалните ИТ компании гледаат на инвестирањето во вакви custom QA алатки?
Локалните ИТ компании сè повеќе ја разбираат вредноста на подобри QA алатки, но многу често иницијативата доаѓа од самите QA инженери.
Затоа ги охрабрувам QA инженерите кај нас да бидат проактивни, да пробуваат нови алатки, да мерат што им носи вредност и да споделуваат искуства. Oracle е бесплатен и достапен, лесен за имплементација, а јас сум отворен за feedback, прашања и проблеми — било преку LinkedIn, GitHub или директна комуникација.
Каде ја гледаш улогата на QA инженерот во ера на автономно рапортирање и AI анализа?
QA позицијата моментално поминува низ многу важна и позитивна транзиција со помош на AI. За QA инженерите, AI не е закана, туку силна алатка. Би рекол дека е „superpower“ за она што веќе го работиме: анализа, автоматизација, test design, debugging, документација и развој на сопствени алатки.
Денес сè повеќе код се пишува или се асистира со AI, што значи дека улогата на QA станува уште поважна. Некој мора да го разбере ризикот, квалитетот, корисничкото однесување и последиците од промените.
Затоа идниот QA инженер нема да биде само некој што извршува тестови. Тој ќе биде инженер кој знае да анализира системи, да користи AI, да гради алатки и да носи подобри одлуки за квалитетот на продуктот.
За тимовите што моментално користат стандардни Playwright репортери, колку е тешка транзицијата кон Oracle? Што сè е потребно за еден девелопер да го види првиот „сигнал“ наместо само извештај?
Транзицијата кон Oracle Reporter е намерно направена да биде многу едноставна. Во основа, потребни се неколку команди и една промена во Playwright конфигурацијата, каде што default reporter-от се заменува со Oracle reporter. Не е потребно тимот да го менува целиот framework или начинот на кој ги пишува тестовите.
Документацијата во GitHub repo-то е детална, но ако некој има проблем или прашање, секогаш сум отворен за комуникација — преку LinkedIn или директно преку GitHub.
Идејата е девелоперот многу брзо да стигне до првиот сигнал: не само лог дека тестот паднал, туку корисна анализа што му помага да разбере што најверојатно се случило и каде да почне со проверка.








