

Тројца млади истражувачи, Стефан Крстески, Матеа Ташковска и Борјан Саздов, од Факултетот за електротехника и информациски технологии (ФЕИТ) во Скопје, се здружија за да го создадат domestic-yak-8B🇲🇰, најдобриот македонски модел за обработка на природен јазик во моментов.
Проектот започна како иницијатива за продлабочување на нивните знаења во областа на вештачката интелигенција, но брзо прерасна во придонес за македонскиот дигитален екосистем. Инспириран од предизвиците и можностите што ги нуди обработката на природни јазици, тимот се фокусираше на креирање на јазичен модел способен да ги разбере и обработува спецификите на македонскиот јазик. Нивната работа отвора можност за понатамошни истражувања и развој на апликации кои ќе го унапредат користењето на македонскиот јазик во современите технологии.
За нивната работа на domestic-yak-8B и процесот за создавање на моделот зборувавме со Борјан Саздов.



Како започнавте да работите на развојот на domestic-yak-8B🇲🇰.
Тимот кој стои зад развојот на domestic-yak-8Bmk го сочинуваат:
Стефан Крстески, магистрант на „École polytechnique fédérale de Lausanne (EPFL)”
Матеа Ташковска, магистрантка на „École polytechnique fédérale de Lausanne (EPFL)”
Борјан Саздов, магистрант на “Факултет за електротехника и информациски технологии (ФЕИТ)” при универзитетот „Св. Кирил и Методиј“ во СкопјеСите тројца го започнавме нашиот академски пат на „Факултетот за електротехника и информациски технологии“ (ФЕИТ) при УКИМ, како колеги од насоката Компјутерски технологии и инженерство (КТИ). Токму тука за првпат се запознавме со концептите на машинското учење и вештачката интелигенција – области што веднаш го привлекоа нашето внимание поради нивниот огромен потенцијал.
Нашата, цел е да придонесеме кон развојот на обработката на јазици (Natural Language Processing – NLP), со посебен акцент на македонскиот јазик. Македонскиот јазик, и покрај својата богата културна и историска вредност, сè уште не е доволно развиен во оваа сфера. Се стремиме да помогнеме во неговата дигитална еволуција и да создадеме решенија кои ќе имаат реално влијание врз примената на јазикот во современите технологии.
Што ве мотивираше да започнете со креирање на македонски LLM и како Domestic-Yak-8B ќе придонесе кон развојот на македонскиот NLP екосистем?
Главната мотивација за создавање на domestic-yak-8B беше желбата да навлеземе подлабоко во процесот на развој на јазични модели. Првично, започнавме со идеја за помал проект, фокусиран на проширување на нашите знаења. Како што напредувавме, проектот постепено прерасна во нешто поголемо, воден од ентузијазмот и предизвиците со кои се сретнавме. Така, стигнавме до создавање на јазичен модел на македонски јазик.
Според нас, покрај моделот, голем придонес има и корпусот од македонски текстови, бидејќи тој претставува генерален ресурс што може да поддржи голем број апликации, како и да придонесе во областа на лингвистиката. Иако корпусот е релативно обемен (40GB), во споредба со ресурсите достапни за другите јазици како бугарски, српски или руски, тој сè уште е ограничен. Доколку беа достапни и дигитализирани повеќе материјали, ќе можевме да изградиме уште поголем корпус, што би резултирало со подобри модели и континуирани подобрувања во оваа насока.
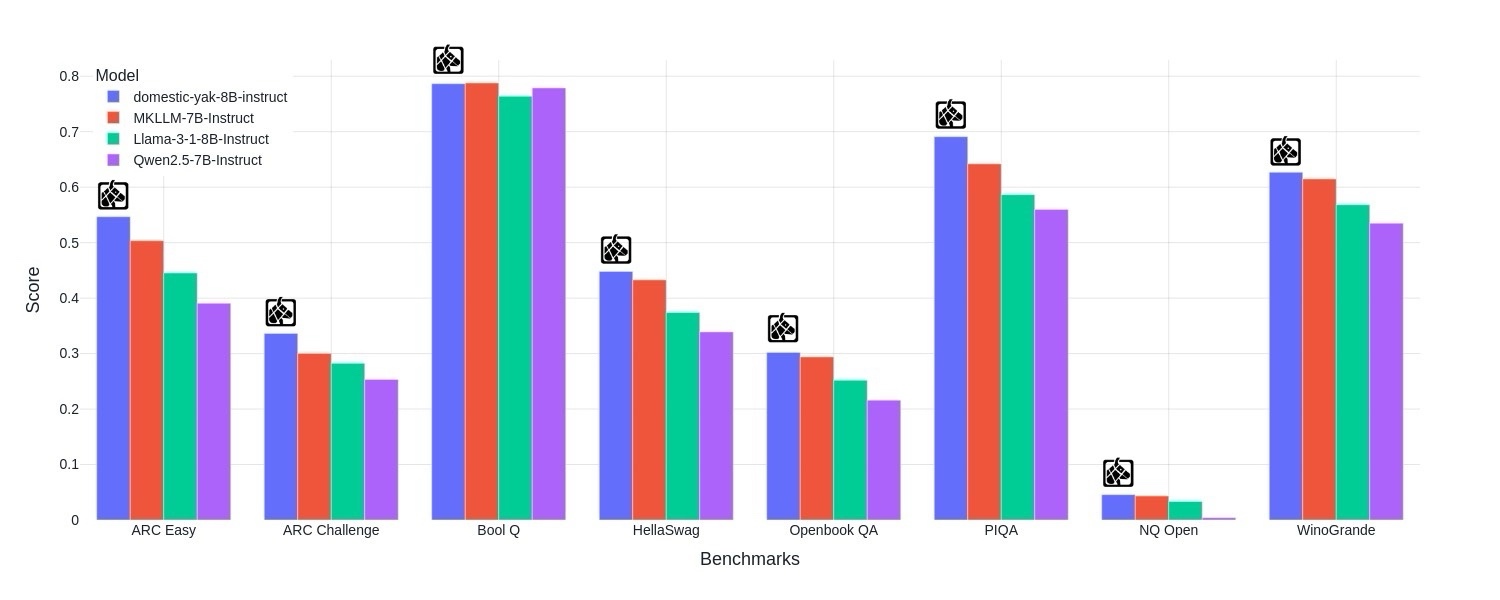
Во моментов, domestic-yak-8B е најдобриот модел на македонски јазик во својата категорија (8B). Благодарение на својата компактност, тој може да поддржи широк спектар на апликации. Моделот заедно со корпусот од македонски текстови, што ги направивме јавно достапни, ќе послужат како основа за понатамошен развој на нови, подобри модели и апликации на македонски јазик.
Можете ли да ни објасните за процесот на создавање на моделот, од собраните податоци до тренирањето на Domestic-Yak-8B?
Процесот на создавање на Domestic-Yak-8B започна со градење на голем корпус на македонски јазик, бидејќи досега немаше јавно достапен ваков ресурс. За оваа цел собравме македонски текстови од различни извори, вклучувајќи книжевни дела, научни и стручни трудови, правни документи, академски публикации и интернет-извори. Некои од изворите беа Македонската академија на науките и уметностите (МАНУ), универзитетите „Св. Кирил и Методиј“ во Скопје, „Гоце Делчев“ во Штип и „Св. Климент Охридски“ во Битола, Институтот за македонски јазик, Службен весник и други релевантни веб извори.
Откако го собравме корпусот, следеше процесот на прочистување и форматирање на податоците за да бидат погодни за тренирање на јазичен модел. Овој чекор вклучуваше филтрирање на текстовите со цел да се отстранат лични информации, неквалитетни содржини, дупликати и извадоци од странски јазици. По оваа подготовка, започнавме со континуирано предтренирање (continuous pretraining) на основната верзија на моделот, базирана на LLaMA 3.1 8B од Meta, кој е достапен за истражувачка употреба. Овој процес траеше две епохи, овозможувајќи му на моделот да ги научи карактеристиките на македонскиот јазик и да генерира текстови со природен тон.
Следниот чекор беше прилагодување на моделот за следење инструкции и одговарање на прашања. За оваа цел создадовме посебен корпус од прашања и одговори, комбинирајќи различни извори: јавно достапни податоци, преведени примери од други јазици и синтетички податоци генерирани со помош на други јазични модели, како што е GPT-4o од OpenAI. Оваа фаза беше клучна за развојот на Instruct верзијата на Domestic-Yak-8B, која може да одговара на прашања и да асистира во различни задачи на македонски јазик, слично на останатите модели прилагодени за следење инструкции (пр. GPT моделите од OpenAI).
За евалуација на моделот, развивме методологија за тестирање на јазични модели на македонски, користејќи преведени и адаптирани верзии на познати податочни множества за оценување на јазични модели. Според овие тестови, Domestic-Yak-8B покажа најдобри резултати во споредба со другите јазични модели од опсегот на модели со помал број на параметри (~8 милијарди параметри).
Сите верзии на моделот како и податочните множества се јавно достапни на платформата Hugging Face, со цел да ја поттикнеме заедницата да го придонесе кон унапредувањето на македонскиот NLP екосистем. Ги охрабруваме сите истражувачи и ентузијасти да придонесат кон подобрување на Domestic-Yak-8B и развојот на македонските јазични модели.
Tемата за податоците станува сè поактуелна, можете ли да ни кажете како беа собрани и обработени податоците за тренирање на Domestic-Yak-8B? Како обезбедивте дека се почитуваат етичките стандарди?
Со оглед на тоа што не постоеше јавно достапен корпус на македонски јазик, започнавме со градење на податочно множество од различни извори, вклучувајќи академски и научни публикации од Македонската академија на науките и уметностите (МАНУ), универзитетите „Св. Кирил и Методиј“ во Скопје, „Гоце Делчев“ во Штип и „Св. Климент Охридски“ во Битола, како и материјали од Институтот за македонски јазик, Службен весник и други релевантни интернет-извори. За да се осигураме дека податоците се користат во согласност со етичките стандарди, исконтактиравме со горенаведените институции за добивање дозвола за нивна употреба во истражувачки цели. Понатаму, сите податоци беа прочистени со цел да се отстранат лични информации и чувствителни податоци. По оваа фаза, корпусот беше обработен и структуриран во формат погоден за тренирање на јазичен модел, користејќи ја алатката MMORE, развиена од група студенти на швајцарскиот универзитет EPFL, меѓу кои беше и членот на нашиот тим, Стефан Крстески. Со овој пристап се осигуравме дека корпусот се усогласува со етичките стандарди, притоа овозможувајќи основа за понатамошен развој на нашиот јазик во оваа сфера.
Kои се главните предизвици со кои се соочивте при обработката на македонскиот јазик, и како успеавте да ги надминете?
Еден од главните предизвици при обработката на македонскиот јазик беше собирањето доволно голем и квалитетен корпус за тренирање за моделот со цел да се приспособи на јазичните карактеристики на македонскиот јазик. Филтрирањето на нерелевантните содржини беше сложен процес, бидејќи наидовме на текстови што не беа на стандарден македонски јазик, содржеа правописни грешки, неформален или мешан јазик, или пак беа дупликати. За да го решиме овој проблем, применивме комбинација од автоматски филтри, лингвистичка анализа и рачна проверка.
Дополнителен предизвик беше собирањето на податоци во формат прашање-одговор, бидејќи најголем дел од ваквите множества се достапни само на англиски јазик. Автоматското преведување не беше доволно прецизно, па затоа преведените податоци беа дополнително прегледани и коригирани рачно, како и со помош на други јазични модели. Покрај тоа, за да го зголемиме обемот на податоци, искористивме синтетички примери генерирани со помош на напредни јазични модели. Овие податоци беа внимателно проверени и прилагодени за да бидат усогласени со македонската граматика и правопис. Со овие пристапи успеавме да составиме корпус кој му овозможи на моделот Domestic-Yak-8B да ги научи правилата на македонскиот јазик.
Какви се вашите планови за иднина – дали планирате да го надградите моделот или да го примените во конкретни индустрии и апликации?
Секако, планираме да го надградиме моделот, Domestic-Yak-8B е само првиот чекор во развојот на македонските јазични модели. Во наредните верзии целиме кон проширување на корпусот со уште поголем обем на податоци и тренирање на помоќен модел со повеќе параметри. Дополнително, имаме идеја да создадеме помал модел кој ќе биде лесен за тренирање и со кој ќе можеме да експериментираме – односно да ги тестираме најновите достигнувања во оваа брзо развивачка област.
Една од нашите идеи е да го репродуцираме процесот на размислување што го гледаме во модели како DeepSeek R1 и OpenAI O1, со цел да ги истражиме овие пристапи. Сепак, за да го постигнеме ова, потребни се значителни компјутерски ресурси, време и поддршка од заедницата. Што се однесува до практичната примена, моделот има огромен потенцијал да придонесе во различни индустриски гранки преку дигитализација и автоматизација, образовни технологии, преведувачки услуги и многу други апликации што ќе го унапредат користењето на македонскиот јазик во дигиталниот свет.
Како може македонската академска и технолошка заедница да го искористи Domestic-Yak-8B, и кои се вашите очекувања за неговото влијание?
Замислете модел како GPT-4o (кој се користи во ChatGPT) кој е трениран на македонски податоци и ги има научено карактеристиките на нашиот јазик Ваквиот модел отвора безброј можности за применa во академската и технолошката заедница, но и во многу други сфери: од асистент кој им олеснува на луѓето со секојдневните обврски (на пример, пишување известувања, резимеа или мејлови), до алатка која ја поттикнува дигитализацијата и автоматизацијата во речиси секоја индустрија. На пример, може да се користи за автоматско преведување и за проверка на граматика и стил, автоматско сумаризирање на научни трудови и истражувања. Во образованието, може да служи како виртуелен помошник кој помага во објаснување на сложени концепти. Во бизнис-секторот, може да помогне со автоматизирана анализа на податоци, анализа на трендовите на пазарот и подобрување на корисничката поддршка преку интелигентни чет-ботови кои комуницираат природно на македонски јазик. Исто така, во медиумите и новинарството, моделот може да помогне со брза анализа на вести, креирање персонализирани содржини и детектирање дезинформации. Дополнително, моделот може да најде примена и во државните институции преку автоматизација на многу адимистративни процеси. Со правилна интеграција, Domestic-Yak-8B може да придонесе кон дигитализацијата во нашата држава, подобрувајќи ја ефикасноста и олеснувајќи бројни процеси во различни сектори.












