

Непрофитната организација Arc Prize Foundation објави дека создала нов, подобар тест за мерење на општата интелигенција на водечките AI модели. Фондацијата е сооснована од истакнатиот истражувач на вештачка интелигенција, Франсоа Шоле,
Новиот тест е дизајниран да ги надмине ограничувањата на претходните тестови. Во минатото тестовите најчесто користеа „сирова сила“ (brute force). На пример, првиот тест ARC-AGI-1 беше совладан од o3 моделот на OpenAI. Сепак моделот успеа да го помине тестот благодарение на огромна пресметковна моќ. Она што е поважно е дека човечките учесници во новите тестови честопати демонстрираат значително подобри резултати од моделите на вештачка интелигенција. Ова е најдобар показател за големата разлика во начинот на кој луѓето и машините ги решаваат проблемите. ARC-AGI-2 тестот е дизајниран да ги предизвика AI моделите да се прилагодат на нови проблеми што не ги виделе претходно.
Засега ARC-AGI-2 успева да ги збуни моделите. „Попаметните“ AI модели како o1-pro на OpenAI и R1 на DeepSeek постигнуваат помеѓу 1% и 1,3 отсто на ARC-AGI-2. Полошите модели, вклучувајќи ги GPT-4.5, Claude 3.7 Sonnet и Gemini 2.0 Flash, постигнуваат околу 1%.
ARC-AGI тестовите се состојат од проблеми слични на визуелни загатки. Вештачката интелигенција треба да ги разгледа визуелните шаблони, да процени што се бара и да генерира точен одговор. Проблемите се дизајнирани да ја принудат вештачката интелигенција да се прилагоди на нови задачи што не ги „виделa“ претходно.
Најпрво Arc Prize Foundation спроведе тестирање на ARC-AGI-2 со повеќе од 400 луѓе за да се утврди човечката основна линија. Во просек луѓето точно одговараат на 60% од прашањата на тестот. Ова е значително подобро од 1,3 отсто колку што се резултатите на моделите.
Во објава на микроблогот X, Шоле тврдеше дека ARC-AGI-2 е подобро мерење на вистинската интелигенција на AI моделот од првата верзија на тестот, ARC-AGI-1. Тестовите на Arc Prize Foundation имаат за цел да проценат дали AI системот може ефикасно да стекне нови вештини надвор од податоците на кои е обучен.
Шоле вели дека за разлика од претходниот, овој тест ја спречува вештачката интелигенција да се потпира на „сирова сила” за да најде решенија. Тој претходно призна дека ова е голема мана на ARC-AGI-1.
Today, we're releasing ARC-AGI-2. It's an AI benchmark designed to measure general fluid intelligence, not memorized skills – a set of never-seen-before tasks that humans find easy, but current AI struggles with.
— François Chollet (@fchollet) March 24, 2025
It keeps the same format as ARC-AGI-1, while significantly… pic.twitter.com/9mDyu48znp
За да се надминат недостатоците на првиот тест, ARC-AGI-2 воведува нова категорија, ефикасност. Новиот тест бара моделите да интерпретираат проблеми во живо, наместо да се потпираат на меморирање.
„Интелигенцијата не е дефинирана единствено од способноста за решавање проблеми или постигнување најдобри резултати. Ефикасноста со која овие способности се стекнуваат и се користат е клучна, и дефинирачка компонента. Најважното прашање не е – Дали вештачката интелигенција може да се здобие со потребни вештини за надминување на задачата, туку која е ефикасноста или цената?“, напиша соосновачот на Arc Prize Foundation, Грег Камрадт во блог пост.
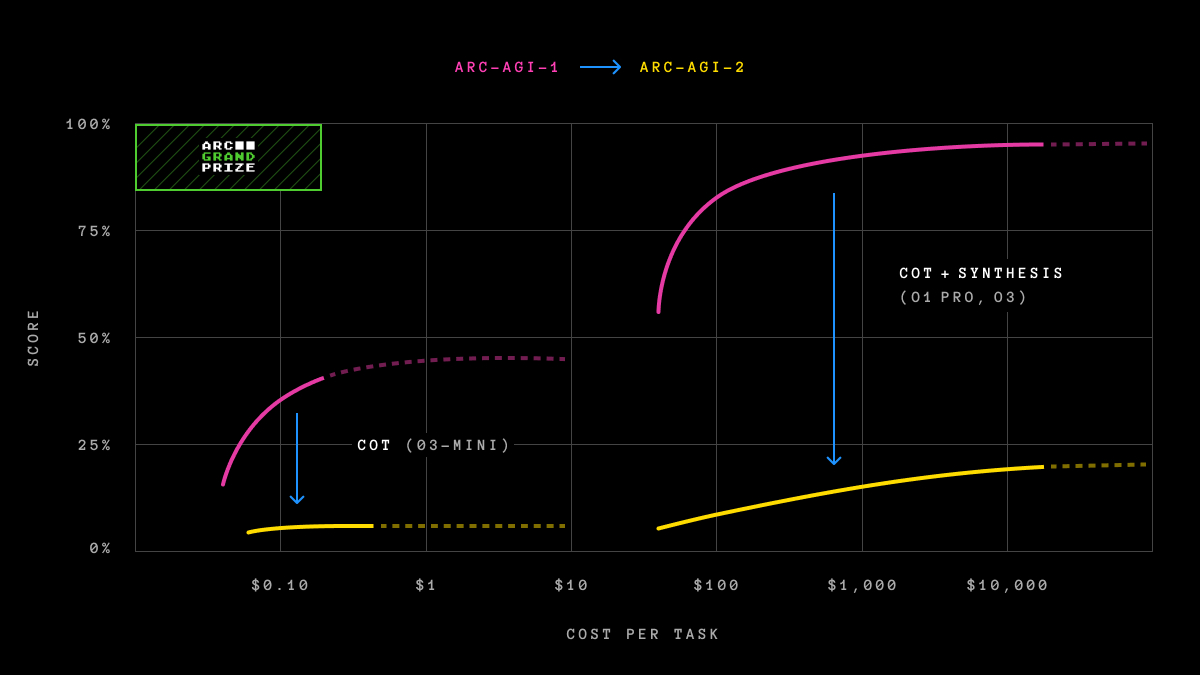
ARC-AGI-1 беше непоразен околу пет години, сè до декември 2024 година, кога OpenAI го објави својот напреден модел за расудување, o3. Овој модел ги надмина сите други AI модели и имаше слични резултати на тестовите како и луѓето, пишува TechCrunch. Сепак перформансите на o3 на ARC-AGI-1 дојдоа со висока цена. Верзијата на моделот o3 на OpenAI o3 (low) која прва достигна врвни резултати на ARC-AGI-1, решавајќи 75,7% на тестот, доби едвај 4% на ARC-AGI-2 користејќи пресметковна моќ од 200 долари по задача.
Покрај новиот тест, Arc Prize Foundation го објави новиот натпревар Arc Prize 2025, предизвикувајќи ги програмерите да постигнат 85% точност на тестот ARC-AGI-2, но да не надминат 0,42 американски долари по задача.




