
Институциите кај нас сè уште ја дефинираат „транспарентноста“ преку објавување на нестандардизирани, непрегледни табели и скенирани документи во кои кирилицата и латиницата се мешаат како лош превод. Гоце Митевски реши да го исчисти овој дигитален шум, наместо да чека бирократијата да се дигитализира, тој користи вештачка интелигенција за да ги направи податоците поразбирливи. Така се роди идејата за Регистарот на јавни претпријатија кој покажува како институциите управуваат со парите на граѓаните.
За Гоце ова не е прв ваков проект. Пред само неколку месеци го создаде Регистарот на лиценци за вршење на угостителска дејност. Овој пат се фокусираше на јавните претпријатија и државните трговски друштва. Ова не е само технички предизвик, туку и увид за тоа како се трошат парите на граѓаните. Сѐ е спакувано во алатка во која секоја загуба од милиони евра е видлива со само еден клик.
Преку комбинација на напредни AI модели како MiniMax, Gemini и Qwen, Гоце успева да открие системски пропусти кои инаку би останале заглавени во нечија фиока или заборавени во PDF формат.
Гоце ни откри која е инспирацијата (или фрустрацијата) која стои зад проектот, за тоа дали македонските институции навистина сакаат да бидат транспарентни и зошто, во ерата на автоматизацијата, најмоќната алатка не е кодот, туку јасната комуникација.

Ова е втор твој регистар и анализа за помaлку од половина година. Која е твојата инспирација овој пат?
Ви благодарам што постојано ја следите мојата работа.
Не знам дали овој пат беше инспирација или фрустрација, но по еден напис за финансиските загуби на јавните претпријатија и трговски друштва, тргнав да барам официјални податоци за да се информирам подобро. Стигнав до страницата на Министерството за финансии и почнав да ги разгледувам извештаите. Сакав да ги видам промените за секое јавно претпријатие и трговско друштво низ годините, но тоа не беше можно преку објавените документи. И така почна сѐ.
Веднаш се отворија прашања како:
- Кое претпријатие имало најдобри, а кое најлоши финансиски резултати во определена година?
- Кој бил директор на одредено претпријатие во определно време?
- Која е официјалната страница на секое претпријатие?
- Кое претпријатие или трговско друштво е расформирано?
- Која политичка партија раководела со одредено претпријатие во определно време?
Дел од одговорите ги добив со регистарот, но за дел недостасуваа податоци или пак беше премногу сложено да се обезбедат.
Проектот повторно ја покажува важноста на отворените податоци, од каде доаѓаат податоците кои ги користиш во анализата?
Податоците што ги обработувам во регистарот се официјални податоци на Министерството за финансии. Тие објавуваат одредени податоци за секое тримесечје, како и годишни извештаи за реализирани приходи и расходи за сите јавните претпријатија и трговски друштва.

Според твоето искуство стануваат ли македонските институции потранспарентни и дали јавните податоци се полесно достапни?
Штом се објавуваат некакви податоци, би сакал да верувам дека македонските институции имаат искрени намери да работат потранспарентно, но сметам дека сѐ уште постои голема дупка од непостоечко знаење за управување со машински обработливи податоци. На пример, ако разгледате на https://data.gov.mk/, ќе видите дека институциите ги сметаат за отворени податоци, документите од тип „PDF“ со скенирана слика во нив или пак со текст, напишан со некаков си прастар, кириличен фонт што не работи со соодветната кодна табела од стандардот „Unicode“. Податоците што не се лесно машински читливи, не може да се сметаат за отворени. Нивната обработка е многу тешка и одзема многу време. Дури ни денешните најнапредни алатки овозможени од големите јазични модели, не можат да помогнат многу.
Велиш дека податоците што ги објавува Министерството за финансии се нецелосни и имаат грешки, имаш ли идеја зошто се јавуваат грешките?
Можам само да претпоставам дека грешките се должат на недоволната машинска писменост на лицата задолжени за управување со овие податоци. Денес има стандарди за речиси сѐ и многу е едноставно доколку се придржувате до стандардите, но ужасно е тешко кога работите се погрешно поставени отпочеток.
Додека го работев регистарот, наидов на една интересна грешка. Бројачот на државни претпријатија за некои од годините упорно ми покажување едно претпријатие повеќе од тие што ги имаше во регистарот. Сѐ беше навидум исто. Со помош на јазичниот модел „MiniMax M2.5“ успеав да откријам дека всушност истото претпријатие, двапати е различно внесено во податоците и разликата е во само една буква… едното име има латинична буква, другото кирилична на истото место. Изгледаат исто, но машински, тоа се две различни вредности.
Вакви слични проблеми во изворните податоци има многу. Бројните вредности се внесени како децимални броеви што претставуваат единици од милиони денари, што значи изворните податоци не се сирови, туку веќе обработени и заокружени, па за да се дојде до целите бројни вредности мора да се прави дополнителна обработка. Ова би било многу поедноставно доколку изворно се внесени цели броеви. Да броевите се многу големи, но тоа не би требало да претставува никаков проблем за внесот.
Понатаму, во македонскиот јазик се користи запирка за одделување на децимални вредности, а точка за илјадарки. Тоа се разбира е испомешано во изворните податоци, па и за тоа беше потребна дополнителна обработка. Да не зборувам за печатните грешки во имињата на претпријатијата, погрешната употреба на интерпункциски знаци итн.
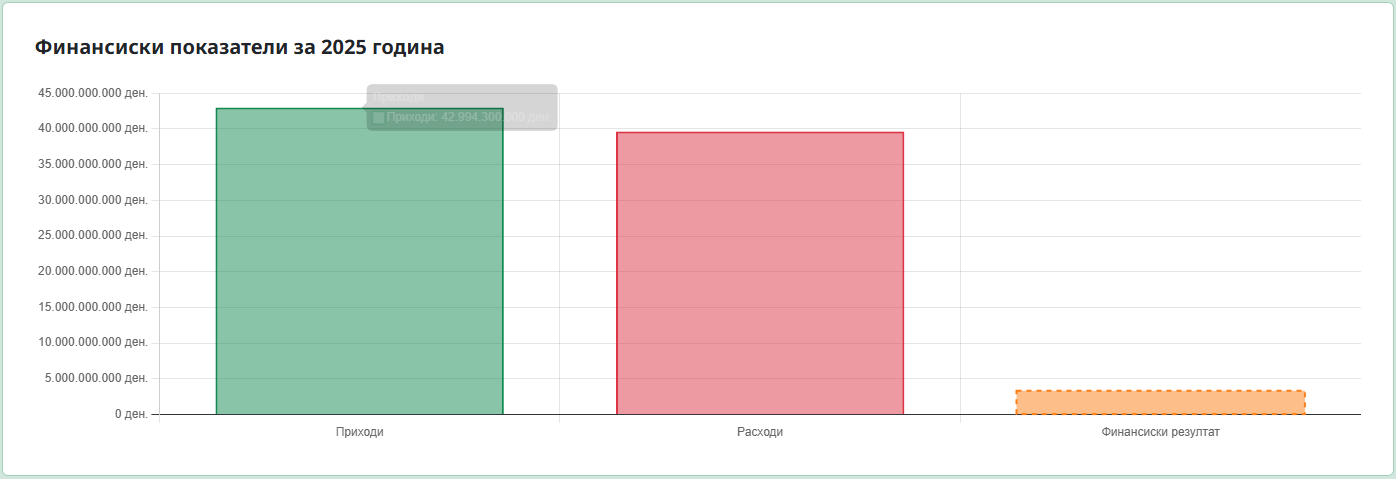
За изработка на проектот користеше вештачка интелигенција. За што ја користеше и каде најмногу ти помогна?
За сѐ што можеше. Нормализирање на податоците за машинска обработка, поставување на апликациската архитектура, подготовка на повеќејазичните содржини, имплементирањето на филтрите, функционалноста за претворање на валутите… откривање на нестандардни имплементации и поправка на сложени грешки во логиката, документација итн. Мислам дека во целост се согласувам со една неодамнешна изјава на Boris Cherny од Anthropic: „Coding is largely solved“. Со проектов и во пракса, за мене се покажа дека е така.
Зошто се одлучи за комбинација на повеќе модели (MiniMax, Gemini, Qwen)? Дали секој од нив имаше специфична улога во обработката на податоците или во кодирањето преку OpenCode?
Не секој модел беше добар во сѐ. „Gemini“ се покажа добро за нормализирање на изворните податоци од „Excel“, но не го користев за кодирање. „MiniMax М2.5“ работи фантастично за кодирање. Неверојатно е колку брзо прави релативно сложени работи и колку добро подразбира изоставени детали, да не речам колку добар контекст има. Колку што знам, „MiniMax M2.5“ e на нивото на коешто беше „Opus 4.5“ на „Antropic“, значи верзијата пред најновата (4.6) што беше објавена неодамна. Со „Qwen 3.5“ отпрвин немав некое многу позитивно искуство, но откако „научи“ од контекстите на „MiniMax M2.5“ се покажа многу подобро за рутински работи, како рефакторирање на веќе постоечки код, пишуваање на документација, давање на предлози за подобрувања итн.
Колку време ти заштеди вештачката интелигенција? Дали овој проект би бил можен за еден поединец без помош на овие алатки во толку краток рок?
Тешко е тоа да се каже, но факт е дека ме спаси од еден куп здодевни, повторувачки задачи. Би можел да кажам дека времето што ти го заштедува вештачката интелигенција е комплементарно на степенот на комуникациски вештини што ги поседуваш, особено на англиски јазик. Ако знаеш да напишеш што сакаш со едноставни зборови и моделот што го користиш е доволно добар за тоа што сакаш да го направиш, заштедата во време би можела да биде и десеткратна. Според мене, најважната вештина во времето на вештачка интелигенција е комуникацијата. Е сега, за да знаеш со едноставни зборови да објасниш што сакаш, треба да имаш одлично разбирање на проблемот и релативно добра слика или визија за неговото решение. Јас би рекол дека тоа си доаѓа со искуството…
Регистарот на јавни претпријатија и трговски друштва не е некој сложен проект, но дефинитивно ќе требаше многу повеќе време за да го изработам без помош на големите јазични модели.
Кои други технологии ги користеше за регистарот и анализата?
Регистарот е изработен со „React“, „Vite“, „Bootstrap“, „xlsx“ и „Chart.js“. За некои рачни измени во податоците користев и LibreOffice. Графичките дизајни ги подготвив со GIMP и Figma. „OpenCode“ го користев како „CLI“ за локален развој, секако во комбинација со „LM Studio“. „LM Studio“ го користев главно за поставување на локален сервер за комуникација со јазичните модели, како и за тестирање на различни модели.
Целиот код е достапен на GitHub. Колку е важна ‘open-source’ културата за македонската ИТ заедница кога станува збор за вакви граѓански иницијативи?
Јас постојано ги објавувам моите проекти под слободни лиценци. Се надевам дека сум позитивен пример за заедницата и за следните генерациите. Сѐ уште сметам дека негувањето на културата на слободен софтвер е единствениот начин за постојан напредок на човештвото. Изработуваме алатки, алатките се користат за нешто и имаме некаков резултат… Погледнете само до каде стигнавме со „Linux“. Сметам дека моите проекти значително добиваат на тежина кога се објавени со изворниот код, зашто намерата е јасна и нема скриени агенди.
Кои се најголемите губитници на листата? Може ли од овие податоци да се процени кои компании најлошо управуваат со парите на граѓаните?
Може, да. Тоа е видливо уште веднаш на насловната страница, во делот со топ-листите, поточно во делот Најлоши финансиски резултати… Со менување на годината во филтрите, може да се види како се менува рејтингот низ годините.
Според податоците на Министерството за финансии на Република Северна Македонија, изгледа дека АД „Електрани на Северна Македонија“ – Скопје има убедливо најлоши финансиски резултати низ годините. Во 2024 година, ова трговско друштво има финансиски загуби од повеќе од 120 милиони евра!
Споделените резултати од анализата се поразителни, има ли барем нешто што може да влее оптимизам?
Самото тоа што сега имаме алатка со којашто можеме да ја следиме работата на овие претпријатија во мене влева оптимизам. Ќе се потрудам редовно да биде ажурирана со најновите податоци на Министерството за финансии, па и да додадам некои нови можности.
Искрено се надевам дека и самите претпријатија ќе се послужат со регистарот за информирано да донесат одлуки за да го променат начинот на којшто работат. Сепак, парите што ги трошат се предмет на одговорност кон македонските граѓани и сметам дека не е сеедно да бидеш директор на претпријатие што потрошило милиони евра, а не остварило финансиски резултати. Сепак, имаш лична одговорност.
Денес, со помош на регистарот и самите претпријатија можат да ги увидат своите резултати и на некој начин да си оддадат признание за успешно завршената работа. Повеќе од половина од јавните претпријатија и трговски друштва оствариле позитивни финансиски резултати низ годините, што не е за потценување. Од 2019 до 2025 година, вкупните финансиски резултати на сите претпријатија се негативни само во 2024 година, што е уште еден исто така позитивен аспект.





