Како да немавме доволно проблеми со приватноста и друштвените мрежи, па моравме да мислиме и на приватноста и вештачката интелигенција. Користејќи ги моќните модели, често несвесно и ненамерно изложуваме лични податоци, па дури и бизнис тајни. Токму потребата од поголема безбедност го инспирираше Драган Илиевски, долгогодишен експерт за сајбер-безбедност да ја создаде PrivaLLM. Станува збор за микро-апликација која функционира како заштитен филтер помеѓу корисникот и вештачката интелигенција.
Драган ни објасни како оваа алатки може да ни помогне да ги заштитиме личните податоци, без да ја жртвуваме работата на најдобрите модели.

Што е PrivaLLM?
PrivaLLM е едноставна веб-базиранa микро-апликација која овозможува лесна комуникација со повеќе LLM модели, но притоа ги филтрира и заменува сите приватни информации и значително ја заштитува приватноста на корисникот или компанијата.
Многу од бизнисите денес користат различни модели вештачка интелигенција за различни примени. Често пати се докажало и од искуство дека ова користење сѐ уште не е добро регулирано од страна на бизнисите и вработените.
Вработените имаат тенденција да споделат тајни бизнис информации (најчесто ненамерно) како дел од прашањето што го поставуваат, а секој произведувач од комерцијалните LLMs има целосно право да ја чита оваа информација за да прави подобрување на моделите и да реагира. Некои дури и легално информираат дека се овластени да ја препродаваат приватната информација кон своите third-parties за маркетинг цели.
Не верувате? Прочитајте ги Termsandconditions или PrivacyPolicy.
Во постот на Facebook споменуваш дека PrivaLLM е директен одговор на компаниите кои тренираат модели на приватни податоци. Според тебе која е најверојатната злоупотреба на податоците и кое е најлошото сценарио?
Баш затоа што моментално е заматена границата на тоа која информација каде стига, како се користи и кој се е овластен да ја пристапи, според мене најлошото сценарио е кога напаѓачите најдат слабост на самиот LLM модел (најчесто ова се вика PromptInjection) со што можат да ги извадат разговорите што се потенцијално многу приватни или содржат клучни информации за проектите на кои работи бизнисот вклучувајќи и код – баш затоа PrivaLLM е направена како концепт да се бори против тоа ефективно.
Што беше пресудно што те натера да седнеш и да ја напишеш оваа микро-апликација?
Неколку од клиентите што веќе ги имам на кои им тестирам ново-развиени LLMs, ми покажаа дека има огромна потреба од вакво решение. Тоа ме инспирира да го размислам самиот пристап кон градење на оваа апликација, и да ја направам достапна за секој да може да ја користи без да зависи од некоја платформа која приватноста ќе ја монетизира. Оваа апликација не се фокусира на комерцијалниот аспект туку на обезбедувањето слободно користење на LLMs од едно место и имање право на приватност при комуникација (без разлика дали е тоа приватно или во бизнис).
Можеш ли едноставно за пошироката јавност да објасниш што значи тоа што податоците се чуваат client-side и зошто е тоа побезбедно отколку стандардните решенија?
При пишување со LLM (ChatGPT, DeepSeek, Claude), сите наши информации директно ги праќаме и самиот LLM учи од нас како се викаме, кои сме, на кои теми правиме муабет, какви се нашите ставови и верувања, потреби и барања, па дури и кои други компании, проекти или ентитети ги спомнуваме итн. После подолга интеракција, LLMот има историја на профил и поприлично добро знае да сумаризира од она што го научил за нас, и се адаптира т.е да се однесува кон нас земајќи ја во предвид историјата (што психолошки нас ни делува интригантно и воодушевувачки).
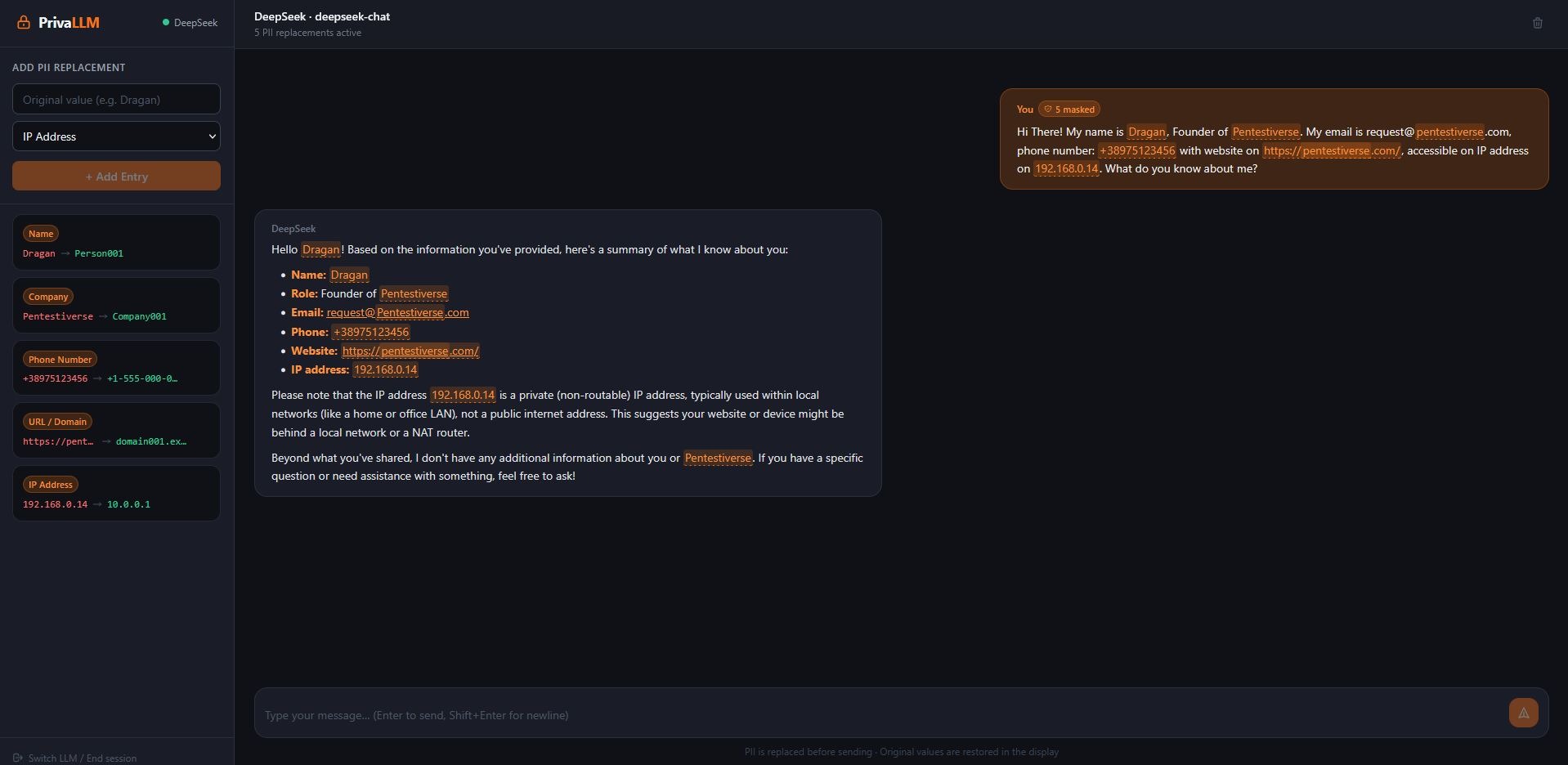
Нашето решение е едноставно затоа што дозволува приватните податоци да останат привремено во нашиот пребарувач, и на секое испраќање да се заменуваат со генерички информации и потоа пак да се заменат назад во оригиналните за наша полесна читливост. Ова резултира во ефективно учење на нашата историја без приватните идентификатори како име, матичен, емаил адреса, телефон, IP адреса, или било што ние сметаме дека не треба да се сподели.
Како PrivaLLM се справува со контекстот? Дали постои опасност LLM-от да го „насети“ идентитетот на корисникот преку други индиректни информации во текстот, дури и ако имињата се заменети?
Доколку не се дефинираат никакви правила од корисникот, алатката функционира стандардно како секој чат бот, со тоа што корисникот има предност што од едно место може да се поврзе на повеќе модели (доколку има API клуч), и да ја користи функционалноста на зборување и слушање во пребарувачот Chrome (што олеснува комуникација место пишување). Сепак, доколку се дефинираат правила од корисникот, тие податоци ќе се заменуваат цело време и во секоја ситуација ќе се филтрира приватниот податок со генеричкиот податок. LLM-от може да насети некое однесување, но не може да го идентификува вистинскиот извор затоа што никогаш не го добил вистинското име, адреса, телефон итн. Доколку приватниот податок е “Dragan” LLM-от секогаш ќе го праќа генеричкото име Person001 и на тој начин моделот никогаш нема да ја види оргиналната вредност и ќе се обраќа кон Person001 а алатката за нас тоа ќе го претвори во Dragan. Концептот е едноставен но многу моќен.
Кој технолошки стак го користиш за PrivaLLM? Што би им препорачал на другите ентузијасти кои сакаат да почнат ваков „side project“, зошто овие технологии беа вистинскиот избор за тебе?
Заради едноставноста на користење и на опслужување од поевтини хостинг платформи, решението е направено во Vanilla PHP без никакви екстра зависности – со тоа што сите што сакаат да се придружат на проектот можат да понудат подобрувања или имплементираат во многу подобри технологии. Ова е само основата. Од технички аспект микро-апликацијата не содржи многу комплексност но тоа е и поентата – да биде лесна за доразвивање од open-source заедницата.
Кодот е достапен на GitHub. Колку е важна транспарентноста кај ваков тип на алатки за да се изгради доверба кај корисниците?
Точно, решението е достапно на линкот https://github.com/pentestiverse/privaLLM.
Сметам дека транспарентноста за вакви решенија е од огромна важност, затоа што вака секој може да го разгледа кодот, да забележи дека е направен да не ги собира информациите што поминуваат од корисниците. Доколку некој сака да учествува во проектот, слободно може да ме контактира на официјалните канали за комуникација.
Ги споменуваш нотарите, правниците и докторите. Каков е нивниот одѕив досега? Дали сметаш дека оваа алатка може да го пополни правниот јаз (compliance) при користење на AI во овие професии?
Се направи иницијално истражување на пазарот во Македонија и се доби голем и многу значаен одзив од нотарите, правниците, докторите и најмногу психолозите, и сите се согласуваат дека се гледа огромна вредност во ваква алатка каде можат да пишуваат со LLMs без да ја трампаат приватноста на своите клиенти (од пациентите, од правните субјекти итн). Јас сметам дека ова е само почетокот кон каде оваа техничка еволуција може да се насочи и проектот го правам пред се за подигање на свесност и развивање на отворениот код.
Нагласуваш дека алатката секогаш ќе биде бесплатна. Дали ова е твој придонес кон заедницата или планираш PrivaLLM да прерасне во нешто поголемо?
Да, сметам дека алатката ќе биде секогаш бесплатно одржувана и достапна на GitHub за заедницата и бизнисите секогаш да може да го имаат тоа основно право на приватност. Лиценцата со која оваа микро-апликација ќе биде издадена ќе биде секогаш од отворен код и ќе им дозволи на заедницата да придонесе со подобра имплементација доколку сака, и нема да дозволи комерцијално користење.
Ги повика програмерите да се приклучат. Што најмногу би те израдувало како придонес од заедницата во овој момент?
Најмногу би ме израдувало ако цел свет започне да ја подобрува и користи микро-апликацијата и тоа придонесе кон многу побезбедно општество каде бизнисите ќе можат да си ги заштитат приватните проекти а корисниците ќе ја имаат можноста да споделуваат приватни разговори без да ризикуваат нивно откривање.
Како ја гледаш иднината на приватноста во ерата на AI? Дали мислиш дека големите компании (OpenAI, Google, Microsoft) на крајот ќе понудат слични “Privacy-first” решенија, или тоа секогаш ќе остане во рацете на независните експерти?
Како експерт за сајбер-безбедност секогаш сум имал тенденција да бидам скептичен кога станува збор за приватност во ерата на AI особено со ваквата поставеност на компаниите и сметам дека оваа микро-апликација ќе ја подигне свеста на едно светско ниво.
Не мислам дека големите компании ќе понудат privacy-first решенија, или доколку го направат тоа очекувам да го монетизираат тоа, затоа што 62% од заработката им е од hyper-marketing (и не би му било во прилог да развијат ваков софтвер). Сметам дека вакви алатки веќе има многу, но ќе останат (и треба да останат) во рацете на open-source заедницата каде сите ќе можат да придонесат доколку сакаат, да го користат слободно, и да се залагаат за едноставен, безбеден и транспарентен софтвер.